On your way to work, you stop by an ATM. Just as you are punching in your secret code, so is a family member punching in their secret code at an ATM across town. You are going to transfer $400 out of an account that has a $500 balance, and your family member is about to withdraw $300 from that same account. Were it not for isolation levels, trouble would be brewing on the horizon…
SQL Server prevents problems that can arise from concurrency situations, such as the above in which concurrent attempts to access and/or modify the same data are made, by implementing six isolation levels. This blog post will help you experience all six isolation levels. As you see them “in action,” you will understand what each one accomplishes and when to use each.
To understand the examples in this post, you will first need to understand what a transaction is and some things about isolation levels. Before we get to the examples, we will cover those topics briefly. The 10776 course, Developing Microsoft SQL Server 2012 Databases, provides a more comprehensive explanation of all the relevant topics.
The examples provided are run against the AdventureWorks database. See Introducing the Examples, below, for links where you can obtain the necessary files to run the examples on your own.
A Brief Introduction to Transactions
All but one of the six isolation levels in SQL Server work by isolating transactions from one another. They are referred to as transaction isolation levels. The other one works at the statement level. We’ll discuss the one statement isolation level at the end of this post. Here, we will start by looking at what a transaction is.
Back at the ATM, you were about to transfer funds between two accounts. Note that the transfer of funds involves at least two data changes; one account needs to be debited and the other one credited. Now, imagine that the debit goes through but the credit fails! You don’t want that to happen, because then you’d lose money. You want both data updates to be treated collectively as a unit of work that either succeeds or fails in its entirety. We call that unit of work a transaction. A transaction is a unit of work against a database that involves one or more changes to data that have to collectively be treated as a single unit—either they all succeed or none of them ever happened.
Here are some more examples of situations requiring multiple data changes that have to either all succeed or never happen: When data are merged into a database, several tables may need to be updated. When a customer places an order, data may need to change in an Order table, an Invoice Line Item table, and a Product table. Purchasing airline tickets may require updates to a passenger table and a reservations table. Whenever an operation requires multiple data changes that have to collectively be treated as a single unit, that’s an example of when a transaction can be used.
We’re ready to introduce two useful concepts at this point—commit and rollback. Data changes that occur in a transaction can only be committed (made permanent in the database) if all data changes in the transaction succeed; otherwise, all the data changes in the transaction made up to the failure point must be rolled back (undone—never happened!).
And now we’re ready to look at some actual commands that allow us to work with transactions. In the examples in this post, we will be using the Explicit Transaction Mode. In this mode, we initiate a transaction with the BEGIN TRANSACTION command. We terminate a transaction with either the COMMIT TRANSACTION or ROLLBACK TRANSACTION command as appropriate.
A Brief Introduction to Isolation Levels
Concurrency situations have to be looked at carefully because they can give rise to known concurrency issues, including dirty reads, non-repeatable reads, and phantom reads that can in turn result in negative consequences for the data as we were about to experience at the ATM (find out more about concurrency issues). We’ve seen that, in order to prevent concurrency issues, isolation levels are used to isolate transactions or statements from each other. Here are the isolation levels by name:
A. Transaction Isolation Levels
-
READ UNCOMMITTED
-
READ COMMITTED (Default)
-
REPEATABLE READ
-
SERIALIZABLE
-
SNAPSHOT
B. Statement Isolation Level
6. READ COMMITTED SNAPSHOT
As you will see in the examples that follow, the higher the isolation level, the higher the level of protection (the more concurrency issues are prevented). Also, each isolation level includes the protections provided by the previous level so that each successively higher isolation level provides added protection in the form of more concurrency issues avoided. But, alas, nothing is free, and so the higher the isolation level, the less data availability there will be. Choosing the appropriate isolation level is a balancing act between highly safe concurrency and high data availability.
Let’s see all this in action.
Introducing the Examples
The examples provided are run against the AdventureWorks database. You can download the AdventureWorks databases (AdventureWorks2008_SR4.exe, which includes all but the 2008R2 versions of the AdventureWorks database)
Download the actual examples provided in this blog post as script files
To create a concurrent environment, all examples use two SQL Server sessions, with each session running a different transaction and with each transaction accessing the same resources. In SQL Server Management Studio, each query window represents a different session, so you can use different query windows for the different transactions in SQL Server Management Studio.
All examples include real word scenarios that allow you to ground all this in reality.
Example 1: The Read Uncommitted Transaction Isolation Level
The Read Uncommitted Transaction Isolation Level provides no isolation at all between transactions and permits one of the most basic forms of concurrency violations, the dirty read. A dirty read occurs when a transaction can read data that have been updated in another transaction but not yet committed.
Use this on a one-user system, on systems in which the likelihood of two transactions accessing the same resources is nil or almost nil, or when using the Rowversion data type to control concurrency.

Example 2: The Read Committed Transaction Isolation Level
The Read Committed Transaction Isolation Level prevents dirty reads by allowing only committed data to be read by the transaction. This is the default transaction isolation level in SQL Server.

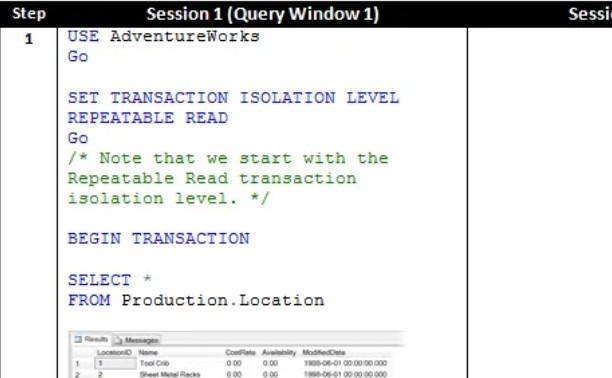
Example 3: The Repeatable Read Transaction Isolation Level
As you read about in steps 2 of the previous transaction isolation levels, the transaction in Session 2 was able to modify data that had been read by the transaction in Session 1. And as the Real Workd Scenario described, this can result in a “lost update.” The Repeatable Read Transaction Isolation Level does not allow this to happen because it would break the Repeatable Read rule; in other words, a read of the same data by the transaction in Session 1 could produce a different result.

Example 4: The Serializable Transaction Isolation Level
Our example will start with the Repeatable Read Transaction Isolation Level in order to show the problem that the Serializable Transaction Isolation Level prevents.

Example 5: The Snapshot Transaction Isolation Level
You may have noticed in examples 1 – 4, above, that concurrency issues are prevented by reducing the availability of data; reads are not allowed, updates are not allowed, or inserts are not allowed. The Snapshot Transaction Isolation Level was developed to prevent many of the concurrency issues prevented by those isolation levels but while reducing the cost associated with higher isolation levels—it allows greater data availability.
It accomplishes this feat by using row versions in TempDB to create a virtual snapshot of the database before the transaction starts. It then only allows the transaction to access that virtual snapshot. This approach is called versioning-based isolation (a complete explanation of the details behind visit Understanding Row Versioning-Based Isolation Levels.
With versioning-based isolation, a transaction sees only the data in that virtual snapshot, so other transactions can still access the same data but only as long as they don’t try to modify data that have been modified by the first transaction. If they do, then those transactions are rolled back and terminated with an error message.
The Snapshot Transaction Isolation Level can only be used after a switch allowing it has been set in the database. Turning on this switch tells the database to set up the versioning environment. It is important to understand this point, because once versioning is turned on, the database has the overhead of maintaining the versioning overhead regardless of whether any transactions are using the Snapshot Isolation Level.
Here’s the example:

Example 6: The Read Committed Snapshot Isolation Level
Up until this point, all the isolation levels have isolated transactions from one another. Resources that are made unavailable to other transactions only become available again once the original transaction completes. The Read Committed Snapshot Isolation Level is different in this regard. It will read data that have been committed by another transaction.
The Read Committed Snapshot Isolation Level is also turned on by means of a database switch. Then, any transactions that use the Read Committed Isolation Level will work with versioning.

I hope these examples help you to understand how to properly isolate transactions and statements from one another to prevent concurrency issues
Enjoy!
Peter Avila
SQL Server Instructor – Interface Technical Training